2.4. Demos: adcp_database_maker.py¶
Scenario:
A UHDAS data directory exists and the preliminary processing needs to be re-done to:
use different settings (eg. averaging length – make shorter averages)
use different serial inputs (eg. a different gps; or compare different feeds)
improve the processing by using newer algorithms
You have VmDAS data and you want a quick look at the LTA (or STA) data. These have already been averaged.
You have VmDAS data and you want to see if CODAS single-ping processing will improve the results.
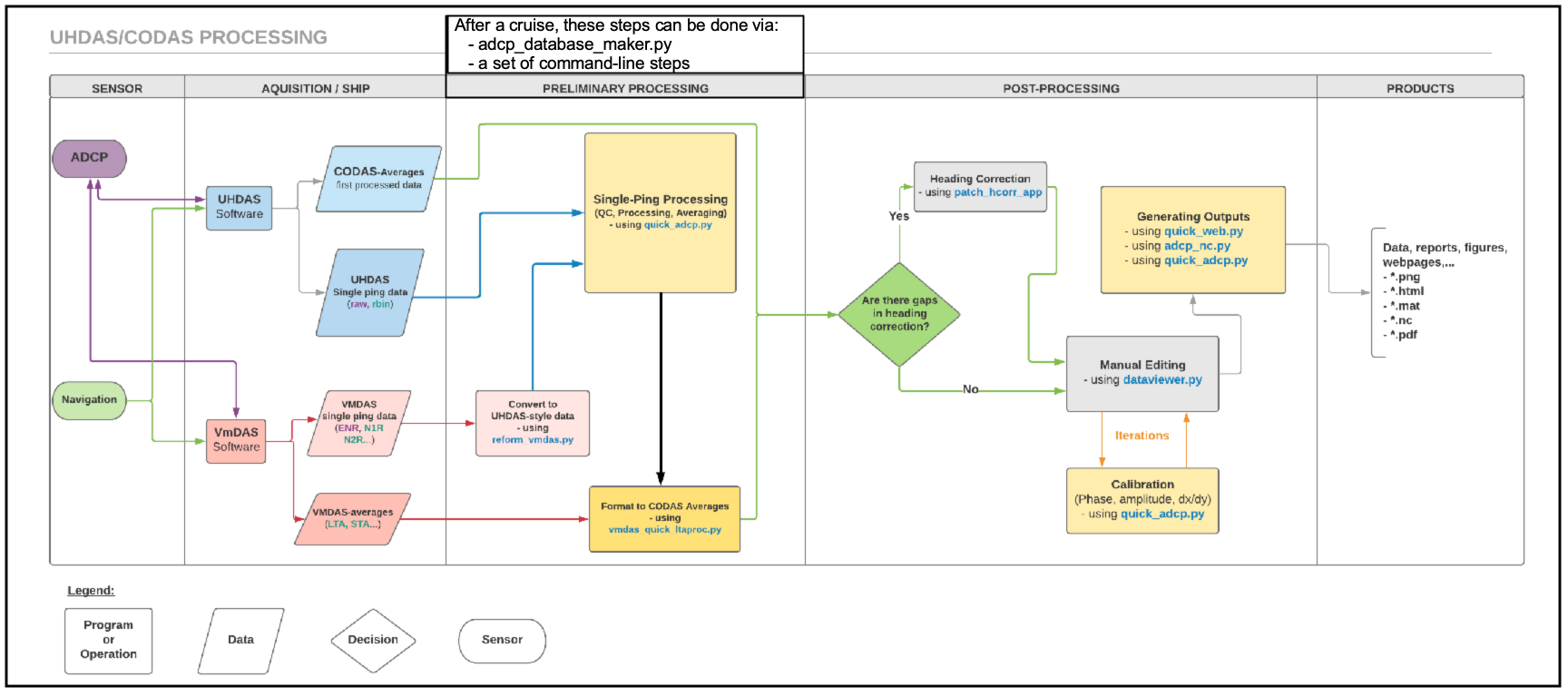
The purpose of running adcp_database_maker.py is to create a directory
structure with averaged ocean currents in earth coordinates suitable
for inspection, editing, and calibration. The figure below shows where
adcp_database_maker.py fits into the flow of data.
To get the most out of this example, you should have already gone through the post-processing demo for UHDAS data.
UHDAS data
You might be reprocessing UHDAS data to:
change the averaging length (eg. 2min instead of 5min)
use newer algorithms on the data
be able to use the postprocessing tools
change the navigation or heading device used in at-sea processing
VmDAS data
At its best, VmDAS data is well-behaved and easy to process.
Under these circumstances, there might not be much difference between the LTA data and a single-ping treatment. But all kinds of things can go wrong, and it is often required that processing start at the single-ping level.
Problems can come from:
poor treatment of time
bad serial data:
too many messages in one port
ill-formed serial data feeds
multiple, independent feeds coming in the same port
too many serial messages coming in (buffer overruns)
feeds without checksums
over-long RS232 line (garbled serial messages)
intermittant loss of power to ADCP
badly-named files (ascii sort not equal time sort)
Some of these will cause LTA processing to fail, and there will be no choice but to attempt to process ENR data (plus serial feeds).
CODAS processing of ENR data requires that the position and heading devices be specified. The preliminary processing of ENR data consists of:
converting the ENR and supporting (
N1R,N2R,N3R) files as if they were logged by UHDAS (new directory structure, new file names, different file boundaries, translateN*Rinto rbins)writing a control file for CODAS processing
processing from scratch as if it were actually UHDAS data
Work Strategy:
Go through the LTA data, scrutinize it, and then decide how to proceed with the
ENR data. When you are done, use dataviewer.py -c to compare the two
processing directories.
The diagram below shows an overview of the flow of information. Click on the image to enlarge.
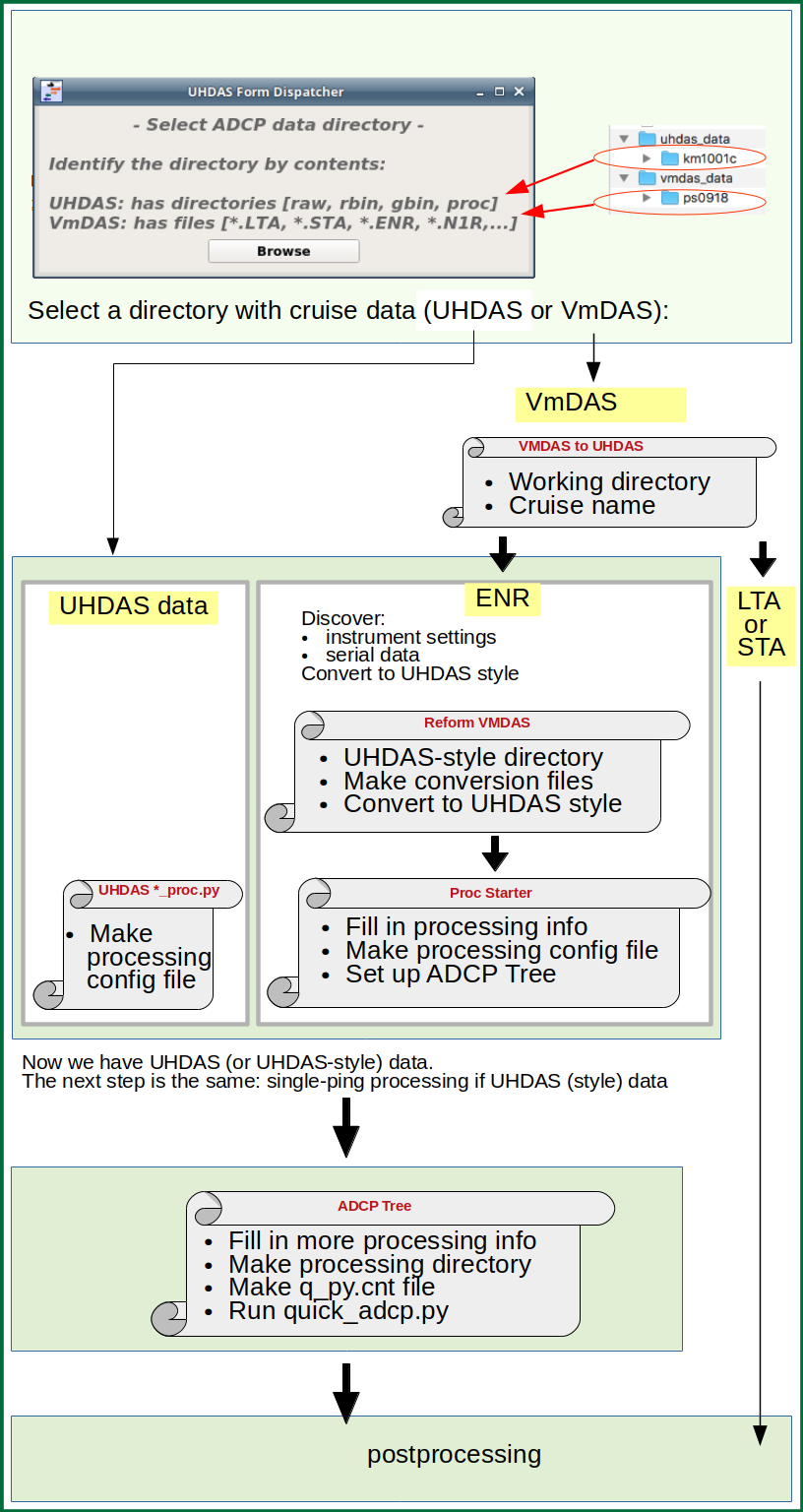
Note
Directory Strategy
To simplify the documentation, these instructions assume you have set up your directories as in Directory Setup and you are doing your processing demos in my_codas_demos/adcp_pyproc
your practice directory source
----------------------- -----------
my_codas_demos
my_codas_demos/adcp_pyproc (new, WORKING IN HERE)
my_codas_demos/uhdas_data copy of codas_demos/uhdas_data
my_codas_demos/vmdas_data copy of codas_demos/vmdas_data
my_codas_demos/uhdas_style_data (new, empty, for VmDAS conversion)