2.5.3. LTA command-line processing¶
Note
Directory Strategy
To simplify the documentation, these instructions assume you have set up your directories as in Directory Setup and you are doing your processing demos in my_codas_demos/adcp_pyproc
your practice directory source
----------------------- -----------
my_codas_demos
my_codas_demos/adcp_pyproc (new, WORKING IN HERE)
my_codas_demos/uhdas_data copy of codas_demos/uhdas_data
my_codas_demos/vmdas_data copy of codas_demos/vmdas_data
my_codas_demos/uhdas_style_data (new, empty, for VmDAS conversion)
Scenario:
This demo shows all the steps to run to get information about the dataset and create the processing directory with LTA data, manually.
Once you have that, you can go to the LTA post-processing demo (next section).
Resources
command-line help:
quick_adcp.py --commands ltapytext file (with metadata) from actual processing directory
dataviewer.py documentation (viewing and editing)
the rest of this web page
Directory Strategy
identify the data files (where the
*.LTAdata are)This work will take place in the project directory
ps0918_vmdas.
example:
cd ~/my_codas_demos/adcp_pyproc/ps0918_vmdas
pwd
The result should be:
/home/adcpproc/my_codas_demos/adcp_pyproc/ps0918_vmdas
2.5.3.1. Discovery¶
Start making notes
In this demo, we will call our textfile manual_lta_notes.txt
find out information about the data
Starting inside ps0918_vmdas, run these commands:
vmdas_info.py --logfile lta_info.txt os ../../vmdas_data/ps0918/*LTA cat lta_info.txt
Look at the file we just wrote (lta_info.txt) and see what can be learned.
Click here
to see an annotated version of the file lta_info.txt
and the locations where the following information are found
Look at vmdas_info.py again and note:
what kind of pings
averaging length
are filenames sorted in chronological order?
what was the heading source?
The output says:
3 files, all have data
averaging length: 300sec
instrument frequency 75
pingtypes: bb pings
bottom track was on for part of the cruise
beam angle 30 (normal for OS75)
transducer angle (EA) 1.18
These were the messages available and what was used:
N1R HEHDT <– VmDAS primary heading
N2R GPGGA N2R GPHDT N2R PASHR,AT2 <– VmDAS backup heading N2R PASHR,ATT N2R PASHR,POS
N3R GPGGA <– VmDAS primary position N3R GPGLL
Start the text file with this information:
--> these are 'bb' pings
--> averaged over 300sec
--> frequency is 75kHz, so "sonar" os "os75bb"
--> primary heading was HEHDT
--> there is an Ashtech, used as secondary heading
2.5.3.2. CREATE PROCESSING DIRECTORY¶
Now that we’ve gotten some information, we can start working
set up processing directory:
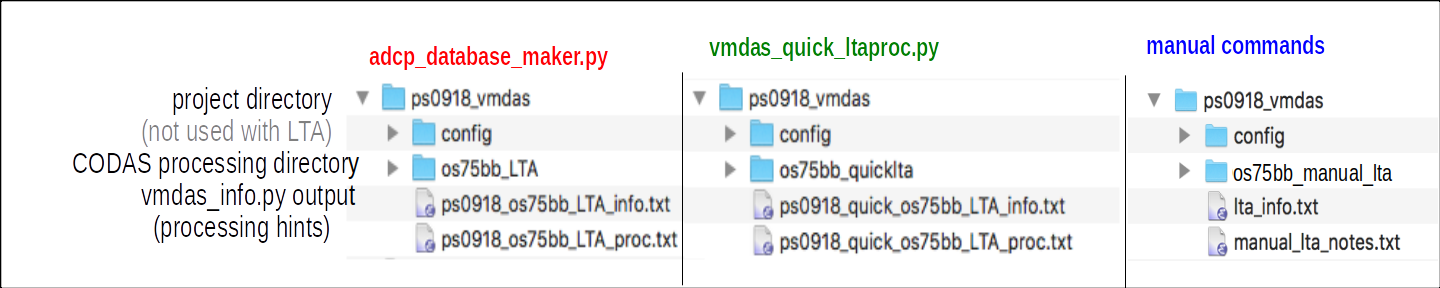
adcptree.py os75bb_manual_lta --datatype lta
Remember to keep your notes in the adjacent file
(i.e. manual_lta_notes.txt) previously created:
Note
Except for editing this text file all the rest of the work will occur inside the directory we just created (os75bb_manual_lta).
2.5.3.3. CREATE CONTROL FILE (q_py.cnt)¶
Note
By default, the LTA files are loaded in ascii sorting order. This assumes the files are in time order when sorted in ascii order. If this is not true, rename them so that ascii order is the same as time order before you proceed. For instance, prepend each file with numbers 01, 02, 03 etc, so they sort in order.
Change directories to processing directory just created:
cd os75bb_manual_lta
Now we make the control file.
Create a quick_adcp.py control file and write the following text in it:
## python processing ##### q_py.cnt is --yearbase 2009 ## required, for decimal day conversion ## (year of first data) --cruisename ps0918 ## always required; used for titles --dbname aship ## database name; in adcpdb. eg. a0918 --datatype lta ## datafile type --sonar os75bb ## instrument letters, frequency, [ping] --ens_len 300 ## specify correct ensemble length --datadir ../../../vmdas_data/ps0918 ##use this option to avoid ## copying or linking files #### end of q_py.cnt
In linux you can also use this shortcut, called a “heredoc”.
Now run it.:
quick_adcp.py --cntfile q_py.cnt --auto
In this processing directory is a file called cruise_info.txt.
Put the contents of that file into the top of your notes file
(manual_lta_notes.txt) and edit the parts needed to make it fit this
cruise. This file contains information that quick_adcp.py was
able to glean from the data, and other parts that it cannot know
(eg. Chief Scientist). Fill those in, and continue to add notes.
The next step is postprocessing – see the next demo.
Available Demos
adcp_database_maker.py
commandline details